
第◯正規化って言葉を見るたびに「どこまで正規化することをそう呼ぶんだァ~~~?」となるので、違いをメモ。
記事内で使ってる画像は、以下のサイトから引用させていただきました。
データベースの正規化(第1〜第3正規形) – Wiz テックブログ
(この記事は、自分が後で見返すために書いてるだけなので、noindexを貼っています)
第1正規形
「1つのカラムに、単一の値(分割不可の値)以外の値を入れるのをやめよう!」なテーブルのこと。
たとえば、👇のようなテーブルを
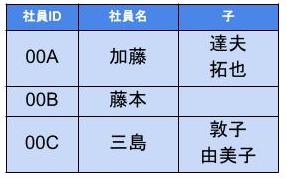
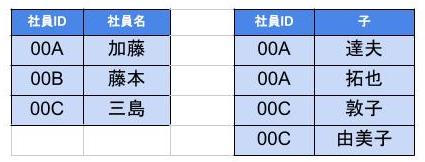
👇のように修正したテーブルのことを第1正規形と呼ぶ。
第2正規形
「主キーが複合キーの場合、複合キーの片方にしか依存していないカラムは排除しようぜ~」なテーブルのこと。
たとえば以下のようなテーブルがあるとします。
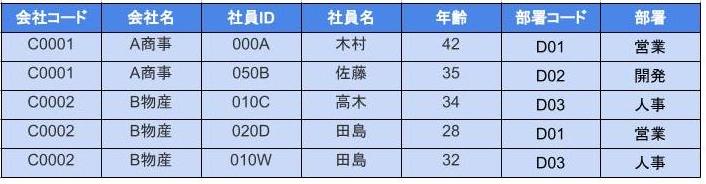
このテーブルは
- 会社コード
- 社員ID
の複合主キーです。
ただし、「社員名」は「会社コード」に関係なく「社員ID」のみによって決まります。
こういう状態のカラムを排除しようよ!というのが第2正規形です。
ちなみに、「社員名」のように、複合主キーの片方にのみ依存するカラムのことを部分関数従属と呼びます。
逆に「社員コード」にも「会社コード」にも、どちらにも依存してるよ~なカラムのことを完全関数従属と呼びます。
要するに、1つのカラムによってだけ決まるカラムのことを完全関数従属と呼ぶ。
このような名前を覚える価値は一切ないと思いますが、覚えておかないと調べ物をしたときに困るので頭の片隅に入れておきます。
👇のように修正したテーブルのことを第2正規形と呼ぶ。

第3正規形
「カラムAはカラムBによって決まるけど、カラムBはカラムCによって決まる。ってことはカラムAはカラムCによって決まるってコト!?」なとき、カラムAのようなカラムは削除しようぜ!なテーブルのこと。
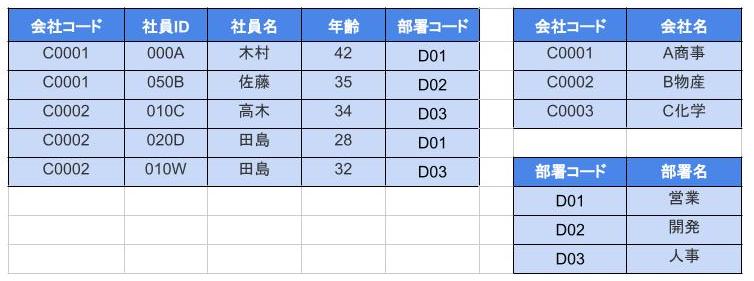
たとえば以下みたいなテーブルがあるとして
このとき、「部署コード」は「会社コード」によって決まります。
さらに「部署」は「部署コード」によって決まります。
ということは、「部署」は「会社コード」によって決まります。
このような関係のことを「推移的関数従属」と呼びます。
👇が第3正規形。
おわり
コメント