
最近知ったんですが、Windowsではキーボードから円記号(¥)の入力はできないらしい。
というのも
- キーボード右上の¥キー
- キーボード右下の\キー
のどちらかを押せば円記号(¥)を入力できますが、どちらを押しても入力されるのは円記号(¥)に偽装されたバックスラッシュ記号(\ )らしい。

皆さんこれ知ってました?
いや正直、これを聞いても「何言ってんだコイツ」って思う人が大半だと思いますし、私も今でもそう思います。
これは「バックスラッシュと円記号問題」などと言って、Windowsで昔から続く”呪い”のようなものらしいのですが
この”呪い”を理解するには文字コードの歴史を知る必要があります。
文字コードとは?
その前に、そもそも文字コードってなによ?という根本的な話からすると、文字コードは「パソコンに文字を覚えさせるための暗記表」みたいなものです。
パソコンは2進数しか理解できないので
- あ:0001
- い:0010
- う:0011
というふうに「この数字が出たらこの文字だよ!」な暗記表をパソコンに覚えさせて文字を理解させるわけです。(まぁパソコンは「この数字が来たらこれを出す」という風に処理してるだけなので”文字”を理解しているわけではないですが・・)
例えば先ほどの例で言うと、「あいう」という文章を打ちたいなら「0001 0010 0011」みたいな感じで伝えれば「あいう」と表示してくれる・・みたいな感じ。
そして、この文字と数字の暗記表のことを「文字コード」と呼びます。
正確に言うと文字コードではなくて「符号化文字集合」などと呼ぶのが正確なのですが、今回はそこは置いといて・・。
文字コードの歴史
文字コードは世界中にたくさん存在します。
なぜなら昔はPCスペックが低かった上に、ネットで他国と交流することもなかったので「自国の文字さえ使えればいいや」という理由から、各国が自国専用の文字コードを作っていたからです。自国の言語だけなら文字コードの量が少なくなりますからね。
その中でも世界で最初に生まれた文字コードを「ASCII」といいます。
日本語読みで「アスキー」です。
ASCIIはアメリカが作った文字コードです。世界で最初に文字コードを作るなんてさすがアメリカですね。
ちなみに「なんでASCIIの話なんかするの?関係なくね?」と思うかもですが、「バックスラッシュと円記号問題」を知る上でこのASCIIを避けては通れないからです。
そして以下が実際のASCIIの文字コードです。
| 16進 | 文字 |
|---|---|
| 0x00 | 制御文字 (なんかいろいろ制御するための文字だと思ってください・・) |
| 0x01 | |
| 0x02 | |
| 0x03 | |
| 0x04 | |
| 0x05 | |
| 0x06 | |
| 0x07 | |
| 0x08 | |
| 0x09 | |
| 0x0a | |
| 0x0b | |
| 0x0c | |
| 0x0d | |
| 0x0e | |
| 0x0f | |
| 0x10 | |
| 0x11 | |
| 0x12 | |
| 0x13 | |
| 0x14 | |
| 0x15 | |
| 0x16 | |
| 0x17 | |
| 0x18 | |
| 0x19 | |
| 0x1a | |
| 0x1b | |
| 0x1c | |
| 0x1d | |
| 0x1e | |
| 0x1f | |
| 0x20 | |
| 0x21 | ! |
| 0x22 | “ |
| 0x23 | # |
| 0x24 | $ |
| 0x25 | % |
| 0x26 | & |
| 0x27 | ‘ |
| 0x28 | ( |
| 0x29 | ) |
| 0x2a | * |
| 0x2b | + |
| 0x2c | , |
| 0x2d | – |
| 0x2e | . |
| 0x2f | / |
| 0x30 | 0 |
| 0x31 | 1 |
| 0x32 | 2 |
| 0x33 | 3 |
| 0x34 | 4 |
| 0x35 | 5 |
| 0x36 | 6 |
| 0x37 | 7 |
| 0x38 | 8 |
| 0x39 | 9 |
| 0x3a | : |
| 0x3b | ; |
| 0x3c | < |
| 0x3d | = |
| 0x3e | > |
| 0x3f | ? |
| 0x40 | @ |
| 0x41 | A |
| 0x42 | B |
| 0x43 | C |
| 0x44 | D |
| 0x45 | E |
| 0x46 | F |
| 0x47 | G |
| 0x48 | H |
| 0x49 | I |
| 0x4a | J |
| 0x4b | K |
| 0x4c | L |
| 0x4d | M |
| 0x4e | N |
| 0x4f | O |
| 0x50 | P |
| 0x51 | Q |
| 0x52 | R |
| 0x53 | S |
| 0x54 | T |
| 0x55 | U |
| 0x56 | V |
| 0x57 | W |
| 0x58 | X |
| 0x59 | Y |
| 0x5a | Z |
| 0x5b | [ |
| 0x5c | \ |
| 0x5d | ] |
| 0x5e | ^ |
| 0x5f | _ |
| 0x60 | ` |
| 0x61 | a |
| 0x62 | b |
| 0x63 | c |
| 0x64 | d |
| 0x65 | e |
| 0x66 | f |
| 0x67 | g |
| 0x68 | h |
| 0x69 | i |
| 0x6a | j |
| 0x6b | k |
| 0x6c | l |
| 0x6d | m |
| 0x6e | n |
| 0x6f | o |
| 0x70 | p |
| 0x71 | q |
| 0x72 | r |
| 0x73 | s |
| 0x74 | t |
| 0x75 | u |
| 0x76 | v |
| 0x77 | w |
| 0x78 | x |
| 0x79 | y |
| 0x7a | z |
| 0x7b | { |
| 0x7c | | |
| 0x7d | } |
| 0x7e | ~ |
| 0x7f | DEL(削除) |
※緑で塗りつぶしている意味については後述します
アメリカが作った文字コードだけあって、アルファベットと記号ばかりですね。
それはさておき、この表を見てみると、ASCIIの文字は0x7f個(10進数だと127個)ありますよね。
これはASCIIが7bitコードだからです。
7bitコードというのは、「7bitを使って文字を表現する」ということです。
なんで7bitだったら127個になるんだ?と思うかもなので一応説明すると
2進数が一桁(1bit)だと
- 0
- 1
という2通り表現できますよね?
それが二桁(2bit)になると
- 00
- 01
- 10
- 11
という4通り表現できるようになり、三桁(3bit)になると
- 000
- 001
- 010
- 011
- 100
- 101
- 110
- 111
という8通り表現できるようになります。
これを七桁(7bit)まで増やすと127通り表現できるようになるってわけです。
ちなみになぜ7bitなのかというと、アメリカとしては「7bitあれば俺たちが日々使う英語や記号を一通り表現できるぜ!」みたいなノリで7bitにしたのかもしれません。
昔はパソコンが低スペックだったため、7bitでさえ「これ以上はもうキツイ」ってな感じだったでしょうしね。
ASCII は不便だぜ!
まぁそんなわけで、ASCIIは7bitしか使えません。
なので文字の数もかなり制限されており、実質的には「使える文字は英語のみ」みたいな状態なわけです。
しかし、パソコンは世界中で使われるので、アメリカが決めた文字しか使えないのでは不便です。
なので「ASCIIを原型にして、ASCIIの”いくつかの文字”を変えたバージョンの文字コードを各国で作ろう!」という動きがはじまりました。
”いくつかの文字”というのは、上の表で言うところの緑で塗りつぶした部分の文字12個です。
要するに「ここの文字はなくても困らないだろうから各国で好きな文字を使えるようにしよう!変えたくない場合はそのままでもいいけどね!」ということなのですが、この動きによって生まれた文字コードのことを「ISO/IEC 646」と言います。
ISO/IEC 646日本版 が元凶だぜ!
ISO/IEC 646には各国版があって、例えば
- ISO/IEC 646(日本版)=日本では JIS X 0201 などと呼んだりします
- ISO/IEC 646(アメリカ版)=これが ASCII です
- ISO/IEC 646(ドイツ版)
みたいに国ごとに作られている感じです。
で、その ISO/IEC 646 の日本版の文字コードが以下です。(ASCII と並べて表示しています)
| 16進 | ASCII | ISO/IEC 646の日本版 |
| 0x00 | 制御文字 | 制御文字 |
| 0x01 | ||
| 0x02 | ||
| 0x03 | ||
| 0x04 | ||
| 0x05 | ||
| 0x06 | ||
| 0x07 | ||
| 0x08 | ||
| 0x09 | ||
| 0x0a | ||
| 0x0b | ||
| 0x0c | ||
| 0x0d | ||
| 0x0e | ||
| 0x0f | ||
| 0x10 | ||
| 0x11 | ||
| 0x12 | ||
| 0x13 | ||
| 0x14 | ||
| 0x15 | ||
| 0x16 | ||
| 0x17 | ||
| 0x18 | ||
| 0x19 | ||
| 0x1a | ||
| 0x1b | ||
| 0x1c | ||
| 0x1d | ||
| 0x1e | ||
| 0x1f | ||
| 0x20 | ||
| 0x21 | ! | ! |
| 0x22 | “ | “ |
| 0x23 | # | # |
| 0x24 | $ | $ |
| 0x25 | % | % |
| 0x26 | & | & |
| 0x27 | ‘ | ‘ |
| 0x28 | ( | ( |
| 0x29 | ) | ) |
| 0x2a | * | * |
| 0x2b | + | + |
| 0x2c | , | , |
| 0x2d | – | – |
| 0x2e | . | . |
| 0x2f | / | / |
| 0x30 | 0 | 0 |
| 0x31 | 1 | 1 |
| 0x32 | 2 | 2 |
| 0x33 | 3 | 3 |
| 0x34 | 4 | 4 |
| 0x35 | 5 | 5 |
| 0x36 | 6 | 6 |
| 0x37 | 7 | 7 |
| 0x38 | 8 | 8 |
| 0x39 | 9 | 9 |
| 0x3a | : | : |
| 0x3b | ; | ; |
| 0x3c | < | < |
| 0x3d | = | = |
| 0x3e | > | > |
| 0x3f | ? | ? |
| 0x40 | @ | @ |
| 0x41 | A | A |
| 0x42 | B | B |
| 0x43 | C | C |
| 0x44 | D | D |
| 0x45 | E | E |
| 0x46 | F | F |
| 0x47 | G | G |
| 0x48 | H | H |
| 0x49 | I | I |
| 0x4a | J | J |
| 0x4b | K | K |
| 0x4c | L | L |
| 0x4d | M | M |
| 0x4e | N | N |
| 0x4f | O | O |
| 0x50 | P | P |
| 0x51 | Q | Q |
| 0x52 | R | R |
| 0x53 | S | S |
| 0x54 | T | T |
| 0x55 | U | U |
| 0x56 | V | V |
| 0x57 | W | W |
| 0x58 | X | X |
| 0x59 | Y | Y |
| 0x5a | Z | Z |
| 0x5b | [ | [ |
| 0x5c | \ | ¥ |
| 0x5d | ] | ] |
| 0x5e | ^ | ^ |
| 0x5f | _ | _ |
| 0x60 | ` | ` |
| 0x61 | a | a |
| 0x62 | b | b |
| 0x63 | c | c |
| 0x64 | d | d |
| 0x65 | e | e |
| 0x66 | f | f |
| 0x67 | g | g |
| 0x68 | h | h |
| 0x69 | i | i |
| 0x6a | j | j |
| 0x6b | k | k |
| 0x6c | l | l |
| 0x6d | m | m |
| 0x6e | n | n |
| 0x6f | o | o |
| 0x70 | p | p |
| 0x71 | q | q |
| 0x72 | r | r |
| 0x73 | s | s |
| 0x74 | t | t |
| 0x75 | u | u |
| 0x76 | v | v |
| 0x77 | w | w |
| 0x78 | x | x |
| 0x79 | y | y |
| 0x7a | z | z |
| 0x7b | { | { |
| 0x7c | | | | |
| 0x7d | } | } |
| 0x7e | ~ | ‾ |
| 0x7f | DEL(削除) | DEL(削除) |
見ての通り、ASCIIと違うのは
- 0x5c:
- ASCII:¥
- ISO/IEC 646の日本版:\
- 0x7E:
- ASCII:~
- ISO/IEC 646の日本版:‾
という2箇所だけです。
つまりASCIIからほとんど変更していないわけですね。
ただ、今回注目したいのは、0x5cの部分です。
円記号問題の元凶がまさにこれなのです。
ASCIIでは0x5cが \ なのに、ISO/IEC 646の日本版では ¥ になっているのです。
「だから何だよそんな昔のコードのことなんて関係ないじゃないか」と思うかもですが、これが大いに関係があるのです。
日本版Windowsでは発売当初から、ISO/IEC 646の日本版をもとにして作った文字コードを使用していたので、\ が存在せず、\ の代わりが¥記号だったのです。
例えば、Windowsのコマンドプロンプトを見てみましょう↓。
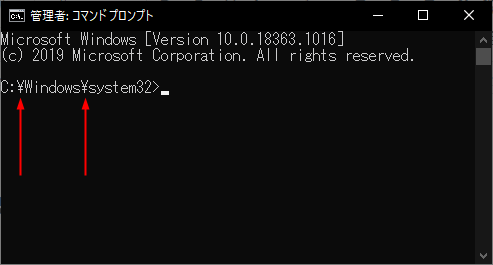
このようにWindowsでは、階層の区切り文字に円記号が使われていますが
実は「区切り文字=円記号」と決まっているわけではなく、本来は「区切り文字=0x5c」というふうに決まっているのです。
つまり、日本は「0x5c」が円記号なので、円記号が区切り文字に使われていますが、アメリカなどのACSIIを使っているWindowsでは区切り文字はバックスラッシュなのです↓。
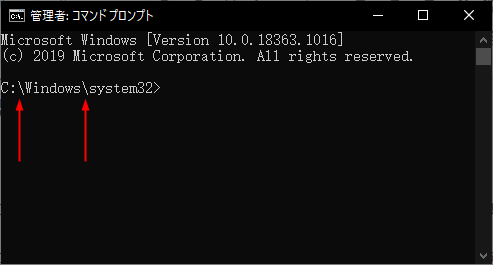
▲米版のWindowsではバックスラッシュが区切り文字
今更修正できない問題・・・
というわけで、ここまで理解できたでしょうか。
- 昔の日本語Windowsにはバックスラッシュがなかった
- Windowsの階層区切り文字は0x5c
- 0x5cは多くの国(というかASCIIを採用している国)ではバックスラッシュだけど、日本では0x5cに円記号が割り当てられてる
- なので日本では、階層区切り文字が円記号になっちゃった
ところで話は変わりますが、Unicodeという文字コードをご存知でしょうか?
Unicodeは「世界中の文字を1つの文字コードにしちゃおうぜ!」という壮大な構想をもった文字コードのことなのですが、最近ではWindowsの内部コードにもUnicodeが使われています。
で、Unicodeは「世界中の文字を1つの文字コードにしちゃおうぜ!」な規格なので、もちろん
- 円記号
- バックスラッシュ記号
の両方が使えます。
具体的に言うと
- 0x5c:バックスラッシュ記号
- 0xA5:円記号
というふうに割り当てられているのですが、つまり今現在のWindowsでは円記号もバックスラッシュも両方使えるのです。
| \ | ¥ | |
| ASCII | 0x5C | 存在しない |
| ISO/IEC 646の日本版 |
存在しない | 0x5C |
| Unicode | 0x5C | 0xA5 |
(厳密に言うとUnicodeでは符号化方式(UTF-8など)と文字集合が別々に定義されているので、バイト列0x5cではなく、U+005cなどと表現するのが正しいと思うのですが、説明簡略化のために0x5cと表現しています・・)
あれ?
そしたら
- キーボード右上の¥キーを押したら・・・
→本来の0xA5(円記号)が出力されるようにする
- キーボード右下の\キーを押したら・・・
→本来の0x5c(バックスラッシュ記号)が出力されるようにする
という風にしたら解決じゃね?
そして今までバックスラッシュの代わりに表示していた円記号をバックスラッシュとして表示したら全て解決じゃね?やったじゃん!
・・・とはならなかったのです。。
なぜならWindowsユーザーの間では、「階層区切り文字=円記号だ!」という認識が刷り込まれているので
「今までの円記号は実はバックスラッシュの代わりだったんだけど、これからはバックスラッシュが使えるようになったからバックスラッシュ使ってね!」
などと今更言っても「は?どういうこと???」と混乱するしょうし、今まで「1,000円」という意味で「¥1,000」と書いていた文章が、ある日いきなり「\1,000円」となっても「どうなってんだこれ」ってなっちゃいます。
なのでMicrosoftは
\ をフォント表示上で ¥ と表示されるように偽装する
ものとし、さらにキーボード上の入力では
- キーボード右上の¥キーを押したら・・・
→0x5c(バックスラッシュ記号)が出力されるようにする
- キーボード右下の\キーを押したら・・・
→0x5c(バックスラッシュ記号)が出力されるようにする
という風にどちらも0x5cが出力されるようにするという、天才的な発想(?)でこの問題を解決しました。
(「え?そんなことしたら余計にユーザーは混乱するんじゃないの?」と思ったかもしれませんが、事実、この記事を読んでいるあなたは円記号とバックスラッシュを特に意識せずにこれまで生きて来たのではないでしょうか?もしそうだとしたらMicrosoftの目論見通りになっています・・)
例えば、適当なエディタを開いて
- \
- ¥
の両方をコピペして、フォントを「Meirio」と「Arial」に切り替えてみてください。

すると
- 「Meirio」ではどちらも円記号で表示されるのに対し、
- 「Arial」ではきちんとバックスラッシュも表示されるのが確認できると思います。
これは
- 日本向けのフォント(和文フォントと呼ばれるもの)では・・・
→0x5cが ¥ として表示されるようにする
- それ以外のフォントでは・・・
→0x5cが本来の \ として表示されるようにする
という仕様になっているかららしいです。
円記号の入力方法
「だったら本来の円記号はどうやって入力すればいいんだ?」という話ですが
「Google日本語入力」IMEを使っている場合は、「えん」と打って変換すれば本来の円記号(0xA5)が入力できます。

Google日本語入力での円記号の入力方法
WindowsデフォルトのMicrosoft IMEの場合は、Google検索で「円記号」などと打って本来の円記号をコピペしてくるか、IMEパッドを使って円記号を入力できます。
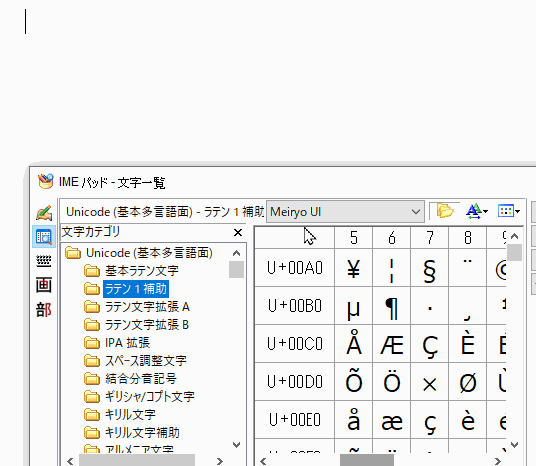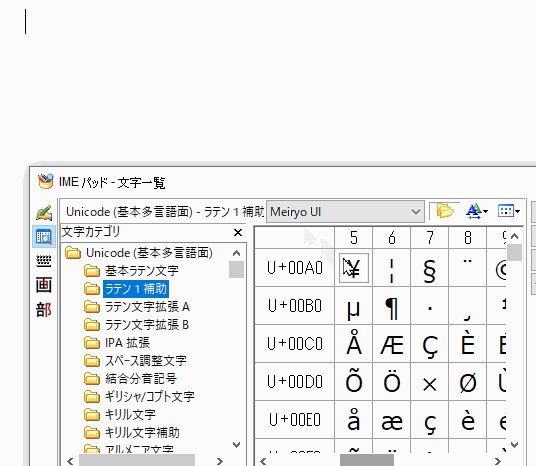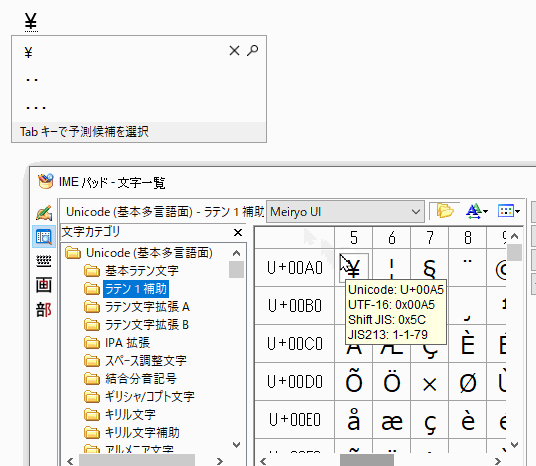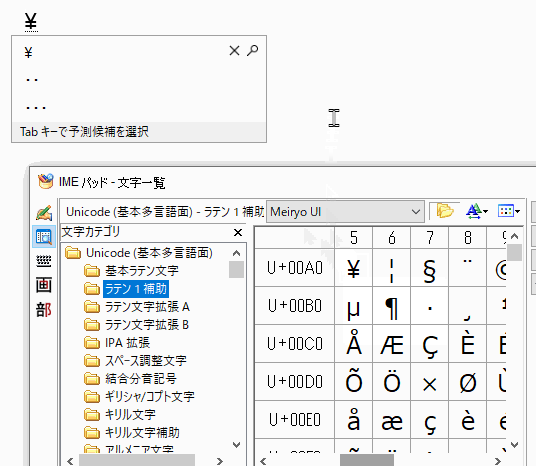
まとめ
というわけで、これがWindowでの円記号とバックスラッシュの問題なのでした。。
いやー、読み返してみてもややこしいですね・・。
ちなみに余談ですが、当ブログの記事はすべて「メイリオ」で書いているのですが(Macの場合はヒラギノ)、すべての文字を「メイリオ」で指定してしまうと円記号とバックスラッシュがどちらも円記号で表示されてしまうので、この記事内ではバックスラッシュの部分だけフォントを「Arial」として表示しています。
なのでこの記事のフォントをすべて「メイリオ」などに変更すると、バックスラッシュも円記号として表示されてしまうのが確認できると思います。
あと本来は記事タイトルにもバックスラッシュと円記号を入れたかったのですが、Google検索結果上では「メイリオ」フォント(Windowsの場合)で記事タイトルが表示されてしまうので、そうするとバックスラッシュも円記号もどちらも円記号として表示されてしまうので、あえなく断念したのでした・・。
おわり
関連:Windowsのパス区切りをバックスラッシュに変更する方法
ちなみにですが、私は以下の本で今回の話を学びました。(その他の文字コードのことも)

文字コードの知識を体系的に身につけるのにオススメな本だと思うので、興味ある方はどうぞ。
![[改訂新版]プログラマのための文字コード技術入門 WEB+DB PRESS plus](https://m.media-amazon.com/images/I/51M4td-sVGL._SL160_.jpg)

コメント
円とバックスラッシュの問題について、興味深く読ませていただきました。以前から何となくで覚えてましたが、記憶が薄れるたびにこのようなサイトで改めて勉強させていただいてます。
なお、中盤の1番肝心なところに誤りがありますのでご確認お願いいたします。
———————
円記号問題の元凶がまさにこれなのです。
ASCIIでは0x5cが(円)なのに、ISO/IEC 646の日本版では(バックスラッシュ)になっているのです。
返信遅れまして申し訳ございません!
逆になってましたね・・・。
修正させていただきました🙏
ご指摘ありがとうございました!🙇
こんにちは。
「見ての通り、ASCIIと違うのは」の枠内のところ、0x5cのASCIIがバックスラッシュで、ISO/IEC 646の日本語版が円記号と書くのが正しいのではないでしょうか?
macOSですと、BackSpaceの隣の「¥」キーを単体で押すとUnicodeの¥が入力されて、Option+¥で「\」が入力されますよね。今の時代はこうやって明示的に打ち分けられるほうが適切な仕様な気はしますね。(逆に「ろ」のキーではバックスラッシュを打てないですが…)
asciiが世界最初の文字コードって、コロンブス以前にはアメリカ大陸はなかったみたいな世界観すね
軽妙に書かれており、非常に興味深い内容でした。
勉強になりました。